Our landing page advertises that following LoLDraftAI's top suggestion at last pick is worth +4% to +7% predicted win probability. The range is real, and depends on what kind of player we're comparing against. This post lays out both numbers honestly.
Setup
We sampled 10,000 ranked games from the held-out test set, spanning patches 15.10 through 16.08 and elos from Silver up to Master+. For each game, we simulated standard pick order (B R R B B R R B B R) and at each pick position we measured the win-probability lift from swapping a chosen actual player's pick to the model's top suggestion. All prior picks were visible to the model, all later picks were masked as UNKNOWN. Champion suggestions were filtered to picks with at least 0.5% playrate in that role on patch 16.08, leaving roughly 32 to 63 candidates per role.
Riot's API gives us role assignments but not pick order, so for each team we independently shuffle the 5 slots into a random pick order. At step p, the model sees the first ppicks of the B R R B B R R B B R sequence (each team's slots revealed in their own shuffled order); the remaining 10 − p are masked.
Two baselines
The two baselines differ in how we pick which of the p revealed slots to replay with the model's suggestion.
- Naive baseline — uniformly at random among the revealed slots.
- Strongest-visible baseline — the slot occupied by the highest-impact champion among the revealed ones. This is a more realistic proxy for pick order: players tend to save high-impact picks for later, when they have more information.
Champion impact here is the same leave-one-out win-probability metric we show in the analysis UI: how much the team's predicted win rate drops if that champion is replaced with UNKNOWN.
The curves
Naive lift grows monotonically from +3.0% at first pick to +7.3% at last pick — at first pick the model has nothing to react to, and the strongest meta picks already sit around 53% win rate, so blind first pick has a natural ceiling.
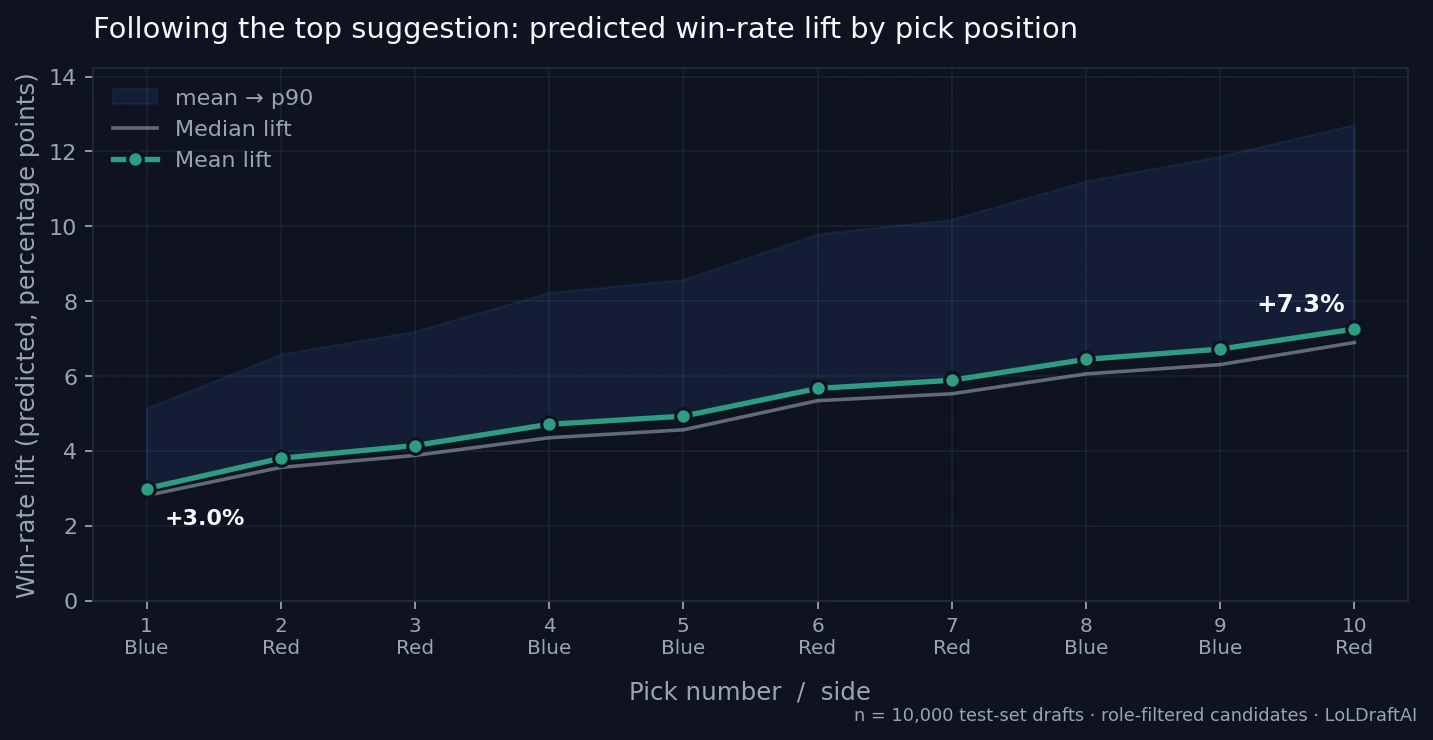
Strongest-visible lift is much flatter. At pick 1 and pick 2 there is only one champion visible per side, so the two baselines are identical. From pick 3 onward the model is competing against the best of k visible picks, which plateaus quickly: the curve sits in a tight +3.5% to +4.1% band for the rest of the draft. By last pick, the +7.3% naive lift has compressed to +3.8%.
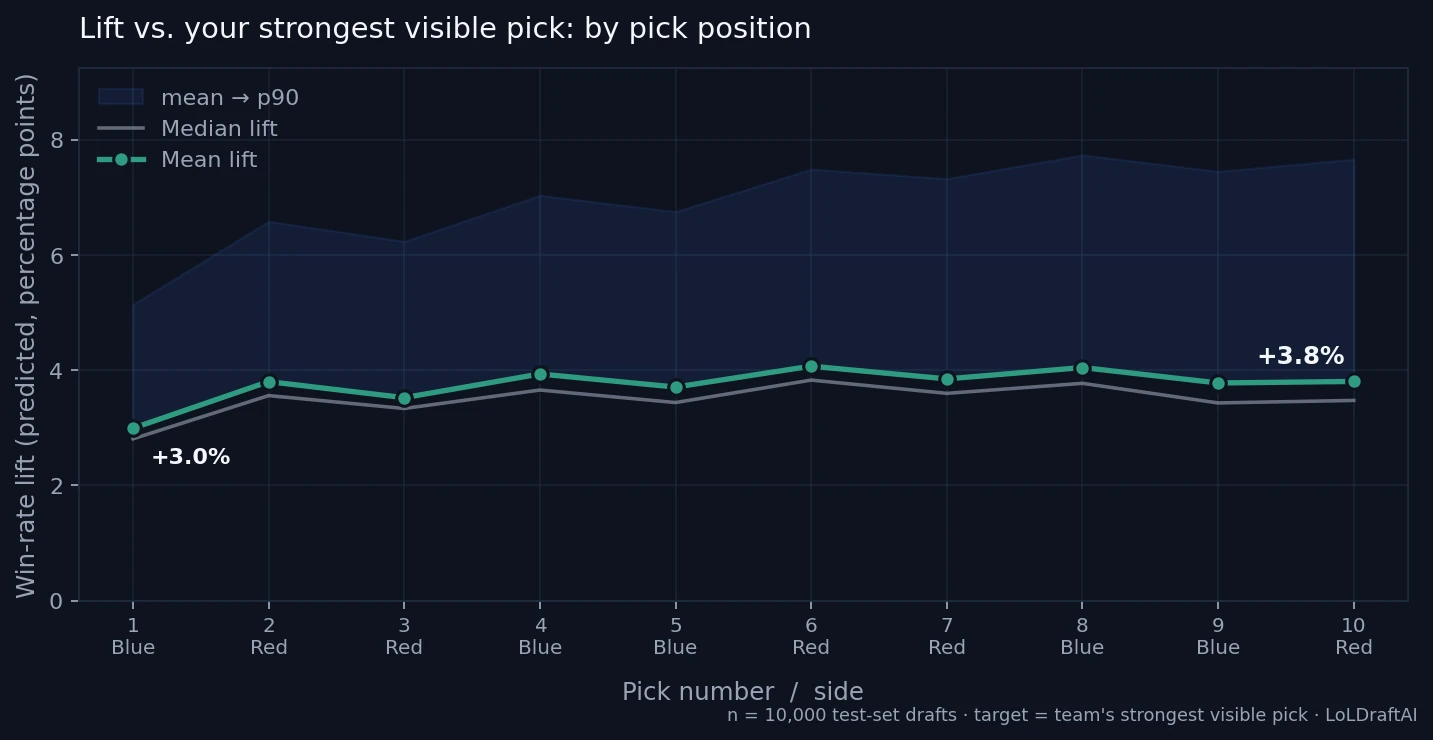
| Pick | Side | Visible picks | Naive baseline | Strongest-visible |
|---|---|---|---|---|
| 1 | Blue | 0 | +3.0% | +3.0% |
| 2 | Red | 1 | +3.8% | +3.8% |
| 3 | Red | 2 | +4.1% | +3.5% |
| 4 | Blue | 3 | +4.7% | +3.9% |
| 5 | Blue | 4 | +4.9% | +3.7% |
| 6 | Red | 5 | +5.7% | +4.1% |
| 7 | Red | 6 | +5.9% | +3.9% |
| 8 | Blue | 7 | +6.4% | +4.0% |
| 9 | Blue | 8 | +6.7% | +3.8% |
| 10 | Red | 9 | +7.3% | +3.8% |
By role and elo
Both baselines show the same ordering across roles — BOTTOM highest, UTILITY lowest — and the strongest-visible baseline shifts every role down by roughly 1 to 1.5 percentage points (BOTTOM: +6.0% naive vs +4.7% strongest; UTILITY: +4.6% vs +3.2%). Across elo brackets the lift is essentially flat in both versions, with a small tilt favoring lower elos (Silver +5.5% / +3.9%, Master+ +5.0% / +3.6%). You don't need to be Diamond+ for the suggestions to be worth following.
Caveats
- This is model-predicted lift, not measured outcomes. The model is well calibrated in-distribution (see the calibration table in our how-it-works post), so the predicted win probabilities are trustworthy at face value, but the lifts are still predictions about predictions.
- The last-pick numbers are the most defensible on either baseline — the counterfactual is fully specified there because no later picks need to adapt. For earlier picks, we implicitly assume the opponent's downstream picks don't change in response to ours, which is unrealistic in a real draft.
- Role-filtering uses a 0.5% playrate threshold in the slot's role on the latest patch.
Takeaway
The headline last-pick lift is between +3.8% and +7.3% depending on the baseline. Under the more realistic baseline — where we assume the strongest pick on the board was the one just made — the model is still worth roughly a +4% win-rate boost. Under random pick order, it's closer to +7%. The truth for any given player sits somewhere in between, depending on their actual counterpick skill.
Try it
Run a draft through LoLDraftAI yourself:
- Web version for analysis
- Desktop app for live draft tracking